AI-agenten voor klantenservice: de 2026-gids voor het verbeteren van KPI & ROI


Het is moeilijk om niet op te merken hoe het gesprek over AI-agenten in de klantenservice langzaam maar zeker het moderne zakelijke discours domineert. We betreden inderdaad het tijdperk van zero-touch resolutie (ZTR) en agentische workflows – concepten die drie jaar geleden nog niet bestonden. Toch bepalen ze nu of een AI-implementatie succesvol is of slechts de illusie van vooruitgang creëert.
Tegenwoordig bedraagt de wereldwijde AI-marktomvang gemiddeld 7,6 miljard dollar, met een verwachte groei naar 47,1 miljard dollar in 2030. Dit is grotendeels een gevolg van het feit dat AI-agenten voor klantenservice al snel genoeg volwassen zijn geworden om complexe, meerstapsinteracties te verwerken. Het probleem waar de meeste bedrijven tegenwoordig mee worden geconfronteerd, is echter AI-gerelateerde kwaliteitscontrole. De vraag is hoe het succes van een AI-implementatie gemeten kan worden, als de meeste bestaande scorecards niet de juiste KPI's bevatten.
Met deze gids willen we niet alleen onthullen hoe AI-systemen nuttig kunnen zijn voor bedrijven bij het behalen van succes, maar ook hoe leidinggevenden kunnen weten of hun AI-agenten daadwerkelijk functioneren.
Laatste nieuws over AI in contactcenters
Het contactcenterlandschap is in de afgelopen 18 maanden drastisch veranderd:
→ Volgens een PwC-onderzoek uit 2025 rapporteert 79% van de organisaties nu een zekere mate van agentische AI-adoptie, en 88% plant die investeringen uit te breiden.
→ Gartner voorspelt dat agentische AI in 2029 autonoom 80% van de veelvoorkomende serviceproblemen zal oplossen.
→ En brancheonderzoek van Calabrio's State of the Contact Center 2025 stelt de huidige AI-adoptie in contactcenters op 98%.
Alles wijst erop dat het pilottijdperk voorbij is. Nu is de voornaamste zakelijke zorg succesvolle uitvoering. Lees voor het volledige overzicht van wat deze verschuiving drijft onze EverHelp contactcenter AI-nieuwsupdate.
Waarom traditionele KPI's falen bij moderne AI-agenten
Verouderde contactcenterstatistieken – zoals Gemiddelde Afhandeltijd (AHT), oproepuitvalpercentage en ticketdeflectie – waren ontworpen voor een wereld waarin elke interactie door een mens werd geleid. Ze zijn nooit bedoeld om iets te evalueren dat 800 tickets tegelijkertijd kan oplossen zonder te slapen.
Volgens onderzoek zegt 64% van de contactcentermanagers dat hun huidige KPI's de klantervaring niet nauwkeurig meten, en slechts 16% zegt de gegevens te hebben die ze nodig hebben om hun klanten echt te begrijpen. In dat gat worden misleidende conclusies geboren. Teams zien de deflectie stijgen, verklaren het project een succes, en missen dat klanten terugkomen.
Want deflectie en resolutie zijn niet hetzelfde. Een gedeflecteerd ticket is er een dat de AI uit de wachtrij heeft geduwd. Een opgelost ticket is er een waarbij de klant kreeg wat hij nodig had en niet terugkwam. Verouderde statistieken vervagen die grens, en vergroten daarmee succeassignalen terwijl ze de problemen stil begraven.
Dit wordt goed geïllustreerd door een veelvoorkomend patroon bij AI-implementaties:
Een team dat CX-automatisering toepast, ziet zijn deflectiepercentage oplopen naar 70%. Het management viert dit. Ondertussen stijgen de herhaalscontactpercentages week na week omdat de AI problemen bevat in plaats van ze af te sluiten. Zonder de juiste voortgangsregistratie kan dat feit maandenlang verborgen blijven – soms lang genoeg om de verkeerde conclusies in de strategie te cementeren.
Klanten die verouderde scorecards meenemen naar AI-projecten lezen consequent hun eigen resultaten verkeerd. Het is niet de kwestie dat AI onderpresteert. Het is gewoon dat de bestaande KPI's eigenlijk niets vertellen over hoe het werkt. Het bouwen van een prestatiearchitectuur moet vóór de automatiseringsbeslissingen komen. En zo ziet de nieuwe standaard eruit.
Top 5 kernstatistieken voor AI-klantenserviceanalyse (per sector)
Eén opmerking: de volgende statistieken zijn geen universele doelen om te halen. Ze moeten meer worden beschouwd als kalibratiepoints, omdat uw benchmarks voortdurend zullen verschuiven afhankelijk van uw sector, uw zoekopdrachtensamenstelling en hoe ver in de implementatie u bent.
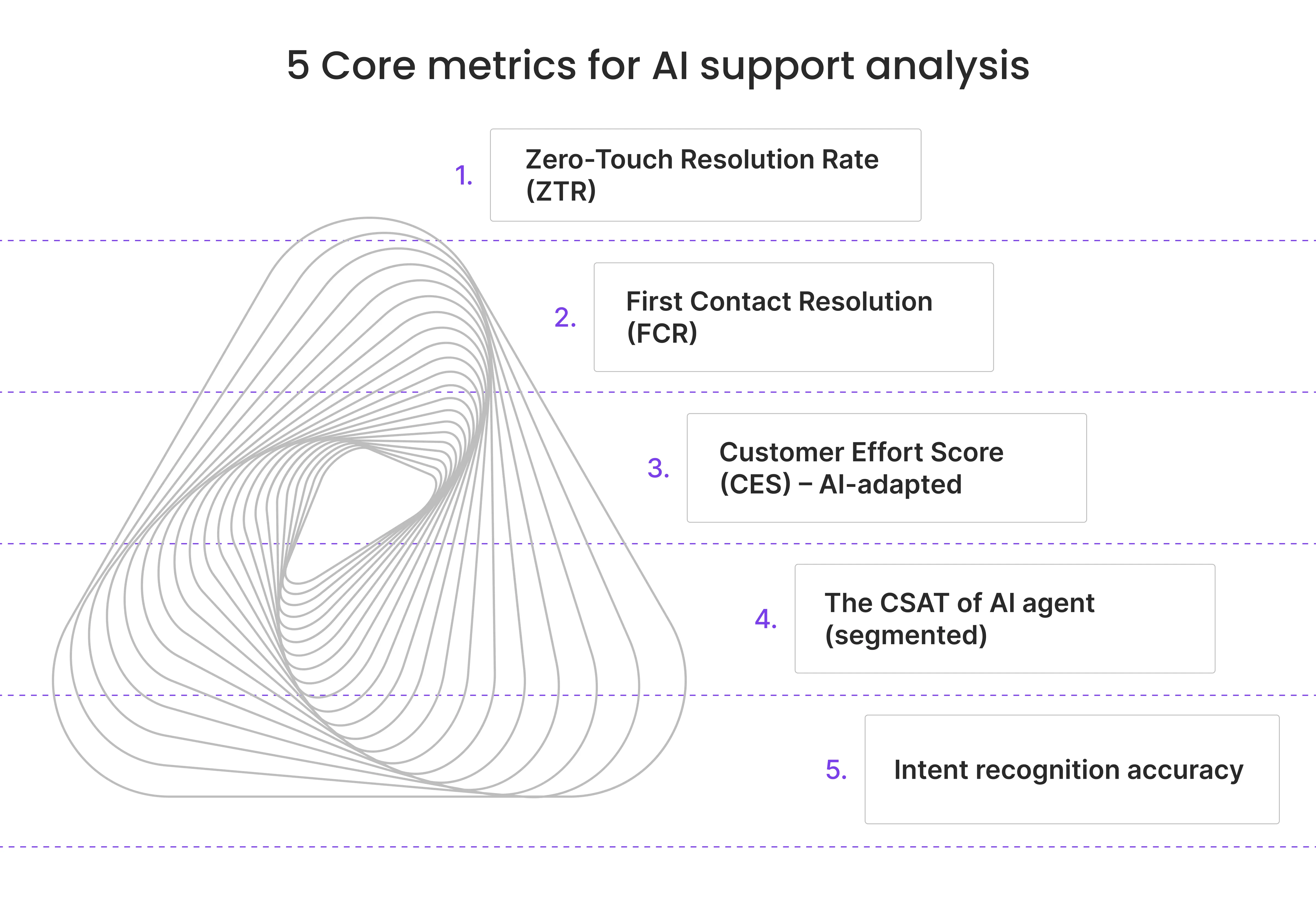
1. Zero-Touch Resolutiepercentage (ZTR)
ZTR is precies wat het klinkt: het percentage problemen dat volledig door AI is opgelost, van begin tot eind, zonder dat een mens de ticket aanraakt. Het is het duidelijkste signaal of u echte ondersteuningsoptimalisatie met AI bereikt of gewoon de overdracht automatiseert.
Branchedoelen voor in-scope vragen liggen over het algemeen tussen 60–80%, maar de sector speelt een rol:
- eCommerce-teams die retouren en WISMO-vragen afhandelen, kunnen realistisch gezien 70–84% bereiken – er zijn veel gestructureerde gegevens mee te werken, en de resolutielogica is goed gedefinieerd.
- Financiële dienstverleners richten zich doorgaans op 60–70%, wat passend is gezien de nalevingsvereisten en de complexiteit van veel accountgerelateerde vragen.
Goed om te weten: wanneer ZTR laag is voor vragen die in scope zouden moeten zijn, ligt de oorzaak bijna nooit bij de AI zelf. Het is meestal een kennisbasegat of een intentieherkenningsprobleem – beide zijn upstream te verhelpen.
2. Eerste Contactresolutie (FCR)
FCR is al tientallen jaren de noordsterstatistiek voor contactcenters. Maar begrijp dit goed – het heeft die status ook in het AI-tijdperk niet verloren. AI verhoogt zelfs het plafond. Toppresterende AI-implementaties kunnen tot 80–85% FCR bereiken, vergeleken met 70–75% voor traditionele centra. Dat verschil neemt in de loop van de tijd toe in zowel klanttevredenheid als kosten.
FCR is ook de moeite waard om te monitoren omdat het signaleert dat de klant op de juiste plek terechtkwam, het juiste antwoord kreeg en geen follow-up nodig had. En de combinatie van lage inspanning en daadwerkelijke probleemoplossing is wat werkelijk loyaliteit opbouwt.
3. Klanteninspanningsscore (CES) – AI-aangepast
Van alle ervaringstatistieken heeft CES de sterkste correlatie met langetermijnmerkloyaliteit: sterker dan verrukking en tevredenheid. In een AI-context is de relevante aanpassing het volgen van 'Pad naar Resolutie'-microacties: hoeveel stappen moest de klant nemen voordat zijn probleem was opgelost?
Operaties van wereldklasse richten zich op minder dan drie microacties per resolutie. Dat betekent geen context herhalen, geen onnodige herauthenticatielussen, geen doodlopende stromen die de klant terugsturen naar het begin. Elke extra stap is een wrijvingspunt, en wrijvingspunten zijn wat klanten laat beslissen of ze terugkomen.
4. AI CSAT (gesegmenteerd)
Dit is waar teams het vaakst de fout ingaan: AI- en menselijke CSAT-scores samenvoegen tot één getal. Het voelt logisch, maar het verbergt het signaal in beide richtingen. Als AI CSAT daalt en menselijke CSAT stabiel blijft, moet u dat weten – en dat weet u niet als u naar een gecombineerd gemiddelde kijkt.
Een solide AI CSAT-benchmark kan ergens tussen 75–84% liggen. Alles wat consistent boven 85% ligt, is van wereldklasse. Als uw totale CSAT is gedaald sinds de AI-uitrol en niemand heeft naar de gesegmenteerde uitsplitsing gekeken, optimaliseert u mogelijk in het donker.
5. Intentieherkenningsnauwkeurigheid
Dit is vaak de laatste statistiek die teams overwegen te meten. Toch, als de AI verkeerd leest wat een klant vraagt – een factuurgeschil doorsturen naar een technische wachtrij, een terugbetalingsverzoek markeren als algemene feedback – treft het rimpeleffect elke andere statistiek op deze lijst. Slechte intentieherkenning verlaagt FCR, verhoogt escalatiepercentages en vermindert CES. En niets wijst terug naar de werkelijke oorzaak, tenzij iemand specifiek de intentieherkenningsnauwkeurigheid in de gaten houdt.
Wat moeten de benchmarks zijn?
- 85% is een operationele basislijn
- 92% is echt goed
- En als u 95%+ bereikt, heeft u de sterkste productie-implementaties.
We raden aan om de intentieherkenningsnauwkeurigheid vanaf de eerste dag van uw AI-lancering bij te houden, omdat het u ook laat zien hoe de AI-klantenserviceagenten die u heeft geïmplementeerd, leren en vorderen.
Geavanceerde technische statistieken die uw aandacht verdienen
De vijf kernstatistieken hierboven vertellen u wat uw AI doet. De volgende vier die we gaan bespreken, vertellen u hoe goed het redeneert. Het zijn deze statistieken die een productiewaardige implementatie onderscheiden van een mooie chatbot met een betere gebruikersinterface.
Contextvasthoudscore (CRS)
CRS meet hoe consistent een AI-agent contextuele feiten toepast over interactierondes heen.
Formule: CRS = Succesvol Toegepaste Contextuele Feiten ÷ Totaal Vereiste Contextuele Feiten.
Productiewaardige agenten moeten een CRS boven 0,90 handhaven over 50+ rondes. Een hoge CRS is een teken dat uw geautomatiseerde agent aanvoelt als een deskundige collega en klanten relevante assistentie kan bieden.
Resolutieduurzaamheid
Weet u of het door AI opgeloste probleem opgelost blijft? Resolutieduurzaamheid vertelt u precies dat, door herhaalscontactpercentages bij te houden op 7 en 30 dagen na de resolutie. Het is een steeds vaker gevolgde statistiek in toonaangevende implementaties, omdat hoge ZTR gecombineerd met slechte Resolutieduurzaamheid een rode vlag is dat de AI tickets bevat, niet afsluit.
Opmerking: Het herhaalscontactpercentage mag na een AI-uitrol niet toenemen.
Escalatienauwkeurigheid
Wanneer u agentische AI implementeert, moet u niet alleen weten hoe vaak de AI escaleert (25–35% is het gezonde doel voor hybride modellen), maar ook of het op het juiste moment escaleert. Beslissingsbomen die activeren op signalen van juridisch risico, emotionele signalen en complexiteitsdrempels zijn wat deze statistiek meet. Volgens Bucher + Suter is escalatieontwerp "het verborgen faalpoint" van AI-implementaties – "het escalatieprobleem is wijdverspreid", en slechte overdrachten zijn een primaire bron van CSAT-degradatie. Het hebben van de juiste escalatietriggers, gebouwd op basis van live interactiegegevens, is de werkelijke reden waarom sommige overdrachten naadloos aanvoelen, terwijl andere leiden tot verlating.
Kennisleemterate
Deze statistiek toont het aantal unieke onbeantwoorde vraagtypen per week. Het zou normaal gesproken in de loop van de tijd moeten dalen naarmate de kennisbase rijpt. Een vlakke of stijgende Kennisleemterate signaleert trainingskwaliteitsproblemen of inhoudsgezondheidsproblemen upstream. Beschouw het als een wekelijkse gezondheidscontrole voor de redenerende brandstof van de AI.
In tegenstelling tot CSAT of FCR is het moeilijk om te misleiden: de AI kan de vraag beantwoorden of niet. Dat maakt het een betrouwbaar vroeg waarschuwingssignaal voordat hiaten beginnen op te duiken in de cijfers die het management daadwerkelijk bekijkt. Voordat u uw benchmarks instelt, is het ook de moeite waard om de volledige afwegingen en voordelen van AI in klantenservice te begrijpen. De winsten zijn reëel, maar de mislukkingen ook, en u moet weten welke u kunt tegenkomen.
{{cta}}
Mens-AI-samenwerkingsstatistieken om bij te houden voor succes
De meeste bedrijven zijn al weggegroeid van de vraag of ze AI moeten gebruiken. Nu vragen de meeste bedrijven zich af hoe ze het succesvol kunnen combineren met de bestaande door menselijke agenten geleide infrastructuur. 85% van de organisaties zet een combinatie van menselijke en AI-agenten in, en 64% van CX-leiders is van plan de investering in AI en gerelateerde technologieën te verhogen, dus de enige vraag is hoe goed ze de overdracht kunnen organiseren.
Er zijn drie statistieken die u kunt gebruiken om te beoordelen of uw mens+AI samenwerking werkt:
- AI-assistentieadoptiepercentage → het percentage agentinteracties waarbij AI-suggesties daadwerkelijk werden gebruikt. Hoewel lage adoptie vaak een UX- of vertrouwensprobleem is, is het altijd de moeite waard om te controleren of er een kwaliteitsprobleem met de suggesties is.
- Escalatietevredenheidsscore → CSAT specifiek bijgehouden na een overdracht van AI naar mens. Een daling hier geeft aan dat het overdrachtsmoment zelf de ervaring schaadt.
- Agent Cognitieve Belastingsindicatoren → volg of AI-assistentie de banen van uw agenten daadwerkelijk beheersbaar maakt. Let op responstijdvariatie (vertragen agenten bij hoog AI-assistentievolume?), stijgende foutpercentages en toename van afhandeltijd.
Wat die drie statistieken gemeen hebben, is dat ze alle drie de grens tussen AI- en menselijk werk meten. Bij het opzetten van een AI-ondersteund systeem is het belangrijk om vast te stellen:
- Waarvoor de AI verantwoordelijk is
- Wat de reikwijdte van de menselijke agenten is?
- Wanneer de AI de situatie moet overdragen aan een mens?
Dat is waarop ons mens+AI-ondersteuningsmodel bij EverHelp is gebaseerd. Want de uitkomsten van die beslissing beïnvloeden uw statistieken (FCR, CSAT, Retentiepercentage, etc.). Technologie is belangrijk, maar procesorganisatie ook.
Voorbij de enquête: realtime sentiment & CX-statistieken
Traditionele CSAT-enquêtes vangen een momentopname na de interactie van één ding: hoe geïrriteerd of tevreden een klant zich voelde toen ze het invulden. AI maakt nu realtime sentimentanalyse over alle interacties mogelijk. Bij de traditionele aanpak was zo'n steekproefpercentage slechts 5%.
Als u besluit te beginnen met sentimentanalyse, let dan extra op de volgende statistieken:
→ Sentimenttrajectorie – hoe de toon van een klant verandert tijdens de interactie.
→ Emotionele escalatietriggers – realtime signalen dat een klant beweegt naar een churrisicotoestand.
→ Doelcompletiepercentage (GCR) – of de klant daadwerkelijk bereikt wat hij is komen doen; het is de moeite waard om dit apart van CSAT bij te houden.
De grotere kans is echter proactieve interventie – problemen vangen voordat een ticket überhaupt wordt aangemaakt. McKinsey's onderzoek naar AI-aangedreven proactieve CX-modellen stelt de impact op 15–20% CSAT-verbetering en 20–30% verlaging van kosten-per-service, specifiek voor organisaties met geïntegreerde, AI-gedreven betrokkenheid gedurende de volledige klantlevenscyclus.
Voorbeeld: Verizon CEO Hans Vestberg verklaarde in 2024 dat de generatieve AI-implementatie van het bedrijf – die 170 miljoen jaarlijkse gesprekken omvat – de reden van een gesprek in 80% van de gevallen kon voorspellen en op koers lag om 100.000 klanten te behouden.
De financiële impact: ROI van AI-agenten meten
Laten we eerst de kernberekening duidelijk maken:
Maandelijkse besparingen = AI-resolutievolume × (menselijke kosten per contact – AI-kosten per contact)
Nu de basiskosten:
- Door mensen afgehandelde tickets variëren van $8–$13,50 aan de lage kant tot $20–$30 aan de hoge kant.
- AI-resoluties kosten $0,99–$3,00.
Met die gegevens kunt u nu de ROI voor uw bedrijf berekenen. Na het analyseren van beschikbare online gegevens hebben we de volgende informatie gevonden over AI-gerelateerde zakelijke ROI:
Belangrijke context: dit geldt alleen voor succesvolle implementaties. Slechts ~5% van de bedrijven bereikt substantiële AI-ROI, en 35% rapporteert gedeeltelijke opbrengsten. De meerderheid ziet binnen de eerste 18 maanden geen meetbare P&L-impact. De ROI-curve is reëel, maar geldt voor de minderheid die de implementatie goed uitvoert.
Bovendien hangt de totale kosten van het AI-agent prijsmodel voor een specifiek bedrijf grotendeels af van de oplossing die u kiest, maar ook van het typische volume aan repetitieve vragen en het type tickets dat verwerkt moet worden.
Het is echter moeilijk te ontkennen dat AI de algehele bedrijfsprestaties verbetert. Het faciliteert klantbehoud, omdat het snelle assistentie biedt precies wanneer klanten dat nodig hebben. En volgens brancheonderzoek zijn consumenten 2,4 keer eerder geneigd trouw te blijven wanneer hun probleem snel wordt opgelost, wat betekent dat snelle resolutie ook een omzetbeschermende factor is voor het bedrijf.
Vergelijking: verouderde chatbots vs. AI-agenten van 2026
Lange tijd waren verouderde chatbots alles wat een bedrijf zou willen, omdat ze eenvoudige tickets met hoog volume weg hielden van menselijke agenten. De meeste organisaties hebben echter nu veel veelzijdigere behoeften. Klantenvragen zijn complexer, verwachtingen zijn hoger, en de operationele lat is gestegen. Als gevolg hiervan bevindt 72% van de ondernemingen zich in productie met of is actief bezig met het pilotten van agentische AI.
Maar wat is het verschil tussen de twee?
Verouderde chatbots vs. AI-agenten van 2026
Casestudy: hoe EverHelp metricstandaarden herdefiniëert met Evly AI
Onze AI-klantenserviceagent, Evly, gelanceerd in mei 2025, heeft al deelgenomen aan 43 implementatiecycli, voornamelijk voor eCommerce- en SaaS-projecten. Onderweg hebben we veel geleerd over het meten van het succes van het AI-product.
De hoofdstatistieken:
- Ticketclassificatie & routeringsnauwkeurigheid → Evly bereikt nu 94%–95%
- Volledig geautomatiseerd resolutiepercentage → we hebben 80% bereikt op de meeste projecten
- Responsnauwkeurigheid → Evly geeft nauwkeurige antwoorden in 90% van de interacties.
- Eerste responstijd → gemiddeld 15–30 seconden met Evly.
Toen we Evly voor het eerst aan onze klanten introduceerden, introduceerden we ook aangepaste scorecards met statistieken om classificatie- en escalatienauwkeurigheid, ZTR, resolutietijd en duurzaamheid bij te houden. Al deze KPI's hebben ons geholpen de prestaties van Evly bij te houden en de lopende training dienovereenkomstig te kalibreren. Zonder dat hadden we niet bereikt wat we nu hebben.
Als u meer wilt weten over onze AI-implementaties, bekijk dan ons AI in Klantenservice Handboek voor meer details en casebeschrijvingen.
De EverHelp-lessen — 4 pijlers van een hoogpresterende AI-agentstrategie
Door onze ervaring met het implementeren van Evly hebben we veel praktische kennis opgedaan, met name over wat de lancering van een AI-agent succesvol maakt. Hier zijn onze belangrijkste lessen:
- Instrumenteer voordat u automatiseert.
Verbind uw contactpunten en stel de analyses in voordat de AI live gaat. U kunt problemen niet oplossen als u ze niet ziet, en blind vliegen in de eerste paar maanden is een dure manier om te leren. - Definieer "opgelost" voordat u lanceert.
De AI doet precies wat u het vertelt te doen. Als u niet heeft gedefinieerd hoe een succesvolle resolutie eruitziet (met escalatietriggers en nalevingsdrempels), zult u geen zinvolle automatisering zien. - Scheid uw kennisbronnen.
Houd een AI-specifieke kennisbase bij die alleen bevat wat klanten moeten zien en wat uw AI kan gebruiken. Interne documentatie in dezelfde pool mengen is de snelste route naar hal


Help iemand anders op de hoogte te blijven. Druk op die deelknop!


.webp)